百度翻译服务器技术细节?百度翻译背后的工作原理?
- 数码维修
- 2025-04-16
- 49
- 更新:2025-04-08 20:38:03
title:揭秘百度翻译服务器:技术细节与工作原理
开启智能翻译之旅
在信息技术迅猛发展的今天,机器翻译作为人工智能领域的重要组成部分,已经广泛应用在我们日常生活的方方面面。作为中国互联网巨头之一,百度推出的翻译服务让跨语言交流变得更加便捷。百度翻译是如何实现的?本文将带您深入探索百度翻译服务器的技术细节和背后的工作原理。

一、百度翻译服务器技术细节
1.1翻译模型与算法
百度翻译的核心技术之一是基于深度学习的神经机器翻译(NeuralMachineTranslation,NMT)模型。NMT模型采用端到端的方式,将源语言文本转换为目标语言文本。百度在这一领域取得了多项创新,比如使用注意力机制(AttentionMechanism)和序列到序列(Seq2Seq)的学习架构,显著提高了翻译质量。
1.2数据处理与存储
翻译服务器处理的数据量巨大,百度翻译拥有强大的数据预处理能力,包括文本清洗、分词、词性标注等,确保翻译模型接收到的数据是准确和高效的。百度的存储解决方案为大规模数据的存储和检索提供了保证,使用分布式文件系统以及高效的键值存储系统来管理数据。
1.3实时处理与高并发
为了满足用户的高并发请求,百度翻译服务器采用了集群技术,通过负载均衡器将翻译请求分散到不同的服务器上。这保证了即便在高峰时段,用户依然可以获得快速响应。百度的实时处理技术使得翻译过程几乎无需等待,实现流畅的用户体验。

二、百度翻译背后的工作原理
2.1翻译流程
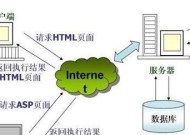
百度翻译的工作流程从用户的输入开始,通过前端界面上传文本或文档到翻译服务器。服务器接收到请求后,先进行语言自动识别,然后根据识别结果选择相应的翻译模型进行翻译。翻译完成后,翻译结果返回给用户,并显示在前端界面上。
2.2语言模型与语料库
百度翻译背后使用了庞大的语料库和先进的语言模型。这些语料库包括了多种语言的平行语料(源语言和目标语言的对照文本)。机器学习模型通过这些数据进行训练,以识别和学习语言之间的对应关系和转换规则。
2.3持续学习与优化
百度翻译利用持续学习机制不断优化模型,通过用户反馈和实际使用数据来迭代更新翻译质量。这种机制确保翻译服务随着时间的推移而不断进步,满足用户不断变化的需求。

三、用户交互与功能扩展
3.1用户界面设计
为了提升用户体验,百度翻译的用户界面简洁直观,支持文本翻译、文档翻译以及网页翻译等多种形式。用户可直接在网页或通过百度翻译App进行翻译操作,界面设计兼顾美观和实用性。
3.2功能拓展与集成
百度翻译不仅提供基础的翻译服务,还集成了语音识别和语音合成技术,提供听和说的能力。百度翻译也支持API接入,方便开发者集成到各种应用场景,如网站、移动应用和企业系统中。
四、常见问题解答
百度翻译支持多少种语言?
百度翻译支持上百种语言的互译,不断更新加入新的语言对,满足全球用户的多样需求。
百度翻译的准确性如何保证?
百度翻译通过不断的算法优化、大规模数据学习以及持续的人工校对来保证翻译准确性。同时,用户也可以提供反馈帮助进一步提升翻译质量。
百度翻译支持离线使用吗?
目前,百度翻译的大部分功能是在线使用的。但百度也在探索离线翻译的可能性,以服务于那些网络条件受限的用户。
结语:语言障碍的智能跨越
综合以上,百度翻译利用先进的翻译模型和大规模数据处理技术,为用户提供了快速、准确的翻译服务。从语言模型的训练到实时翻译的实现,再到用户友好的交互设计,百度翻译在不断进步中,展现了中国科技企业的创新力和对用户需求的深刻理解。未来,百度翻译有望进一步优化,为全球用户提供更优质的跨语言交流体验。
上一篇:智能手表表盘固定设置步骤?
下一篇:哈苏相机存储卡使用方法是什么?